 06-6657-5130
06-6657-5130 sales@hydrolab.co.jp
sales@hydrolab.co.jp蛇使いな彼女BLOG
【第18回】 PDFから文字起こし①ー(tabula)
2020.09.03

んにちは、皆さん!
今日は以前S家先生から頼まれた仕事で、超―めんどくさくて悪戦苦闘した1件をつらつら書いていこうと思います(笑)
あるとき先生から渡されたもの…
それは数年分の表データ。
頼まれた内容はこの表をPDF形式からエクセルに変換するというものでした。
イメージとしてはこんな感じ。
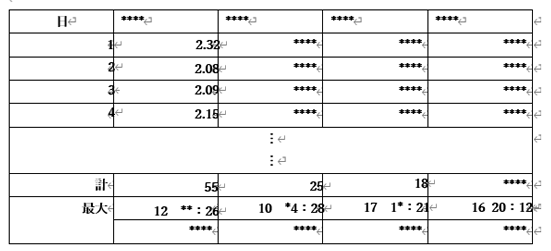
内容公開できない為、文字や詳細は伏せています。(実際はもうちょっときれいです 笑)
ざっと45行13列以上ある不揃いなデータです。
ご覧の通り罫線と数字がひっついてて超絶見づらい。
手作業で打ち込めば見間違いと打ち間違い必至です!
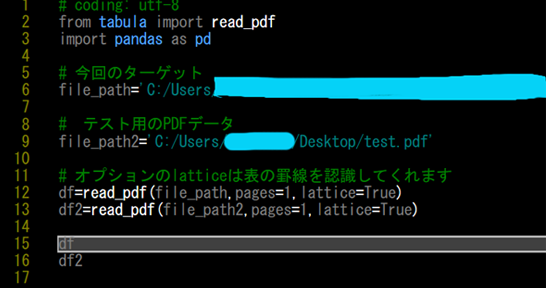
当然Pythonをつかって変換しようと、最初はtabula というライブラリでPDFからcsv形式に変換するプログラムを試していたのですが……
上記のコードでPDFファイルのパスをfile_path、file_path2 という変数に代入してから read_pdfで読み込みを行っています。
file_path は今回変換を頼まれたPDFファイルです。
file_path2 は以下、Excelで作った表をPDF化したテストデータです。
読み込んだ結果は、
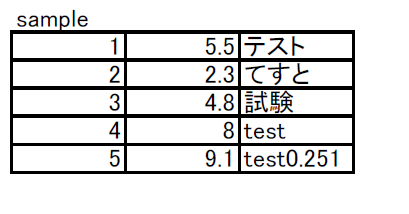
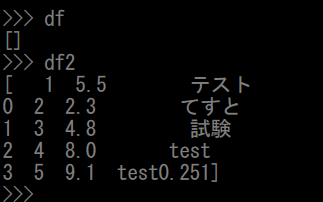
df2のサンプルデータは表内のオブジェクトは読み取れています。
対してターゲットデータ(df)はなせか出力されません
なんで!?と思って元のデータをよ~く見てみると、プリンターのスキャナーで読み込んだ画像データであることが発覚!
そりゃダメだー(´・ω・`)
tabula を使うためにはtalula-pyとjavaのJDKインストールが必要なので(苦手な)環境設定もしたのにこの努力と時間は無駄でした(T_T)
別の方法を探すしかなさそう……
ちなみに標準で搭載されていないライブラリはコマンドプロンプト(ターミナル)にpip install ライブラリ名と打ち込むとインストールできますよ。
この続きは次回 (´;ω;`)
