 06-6657-5130
06-6657-5130 sales@hydrolab.co.jp
sales@hydrolab.co.jp蛇使いな彼女BLOG
【第19回】 PDFから文字起こし②ー(tesseract)
2020.09.17

tabulaを使った簡単な方法は通用しなかったので、気を取り直して今度はPDFを一度画像データにしてから文字を読み取るという方法を試してみました。
今回はtesseractという日本語に対応した文字認識ソフトを使用します!
先のtabulaもそうですが、この手のソフトを使う場合インストールや準備工程に手間が掛かるのでここではその方法は書きません💦(←個人的にめんどくさいだけ)
また、このとき私が実際に使用したコードは複雑なので、ここでは作業のポイントと以下の画像から文字起こしを行う簡単なコード例を記載しておきます。
プログラムで使用する画像(サンプル.png)はこちら↓

POINT1
Anacondaの標準パッケージにないライブラリのインストール。
•import pyocr
Python用のOCRツールラッパー(Pythonからtesseractを使う際に必要)
•PIL
画像処理用のライブラリ(Pillow)
これらをコマンドプロンプトからインストールして下さい。
POINT2
tesseractのインストールと実行方法
•WEBから「tesseract」というソフトをインストールし、Pythonで起動・実行できるように環境変数設定を行います。
•Pythonに以下のコードを入力します。
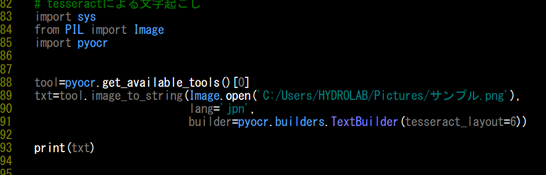
88:tool=pyocr.get_available_tools()[0]
上記のコードではpyocrからtesseractを呼び出しています。
呼び出したときに使用できるツールが有ると推奨順にリスト形式で返ってくるので、末尾に[0]として最適なツールを指定します。
•Tesseractの呼び出しエラーの場合
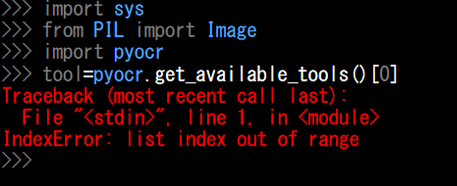
ここでエラーが出た場合、下記のコードを追加してtesseractの実行ファイルの在り処を示してあげます。
pyocr.tesseract.TESSERACT_CMD ='C:/Program Files/Tesseract-OCR/tesseract.exe'
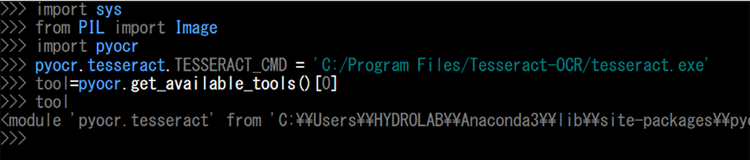
これでツールが返ってきましたね!
私が試した結果、/tesseract.exeまで指定しないとソフトが動きませんでした。
•image_to_string()で文字起こし
それでは画像から文字を抽出します!

106行目、image_to_string()の括弧内では開く画像のパスを指定。
107行目では言語の設定。
108行目ではtesseractのオプションを指定しています(ここではTextBuilder=文字列認識、tesseract_layout=レイアウトパターン)
•結果
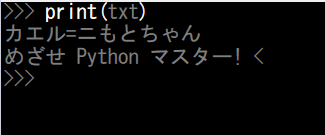
記号の後に誤認していますがテキストはうまく読み込むことができました!
次回、この方法を使った結果
先生から頼まれた例のPDFデータはうまく読み込むことができたのか発表します。
