 06-6657-5130
06-6657-5130 sales@hydrolab.co.jp
sales@hydrolab.co.jp蛇使いな彼女BLOG
【第39回】 htmlファイルからのデータ抽出①ーhtmlファイルの開き方
2021.07.16

やっとここにたどり着きました…。
今回の話題はスクレイピングというやつですよ(‘ω’)!
聞いたことがある方にもそうじゃない方にもわかるように説明すると、スクレイピングとはWEBサイトから情報を抽出する技術のことを指すようです。
例えば、気象データなどWEB上に存在するデータの変更を検出したり抽出したりという使い方が一般的で、すごく便利な反面、Twitterなど一部のWEBサイトでは使用を禁止されているので気を付けましょう。
(ってWikiに書いてありました)
また、スクレイピングとセットでクローリングという言葉をよく見ますが、これはロボットがWEBサイト上の情報を収集する作業を指します。
大手検索エンジンでキーワード検索をした際に関連度の高いWEBページがトップに表示されますよね?
これはロボットが巡回する事によって収集したWEBサイトの情報をデータベース化して、そのデータベースの登録情報から順位を決定し、検索エンジンが各ページの順位に応じて結果を表示するという仕組みで成り立っているのです。
この巡回ロボットにはアルゴリズムやAIも搭載されているらしいですが、企業秘密らしいので詳細不明のようです。一体どんなコードなんでしょうね
(´▽`*)
とにかくこれからクローリング・スクレイピングに挑戦する人はサイトによっては規約違反となる場合があることや、サーバーへ過度な負担を与えない事に注意してみてくださいね。
さてさて、説明はそのくらいにして今日は実際にスクレイピングを試してみたいと思います。
スクレイピング用のライブラリは複数あるのですが、その中でも使いやすかったBeautifulSoupを使った例を紹介します。
★BeautifulSoupでの抽出例
今回スクレイピングで抽出するデータは水位データです。
この前の現場記事で「Sダムに水位計を設置しました~」と紹介したと思いますが、in-situという会社が提供している水位計は、測定データが自動でサーバー上に保存されるようになっています。
ローカル環境に水位データをダウンロードすると(ダウンロードのプロセスは省略します)、このようにhtmlファイルで保存されます。
↓

HydroVu_LevelTROLL500のファイル、これをクリックすると下のページに飛びます。
↓
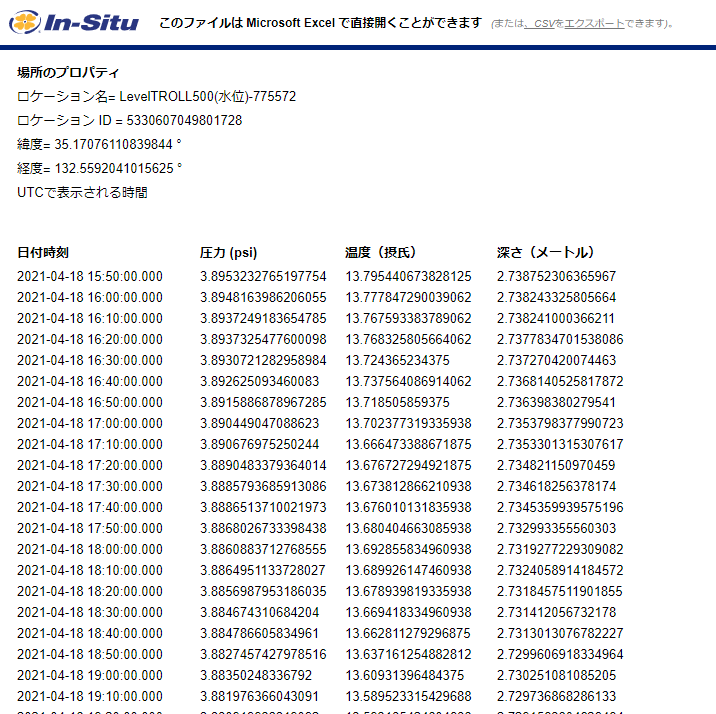
先頭にプロパティとありますが、この下に並んでいる時刻・圧力・温度・深さが測定データです。
ロケーション名、ロケーションIDは水位計の名前とIDになっていますね。
経度、緯度は設置場所の位置情報です。
また、「UTCで表示される時間」とあるように、日付時刻に表示されているのは世界標準時刻なので、これは解析の際に気をつけるポイントですね。
htmlファイルとは、いわばHPの1ページなんですが、私の試してみた限りPythonでこれを読み込む場合はBeautifulSoup以外のライブラリ(…例えばurlを扱う為のurllib.requestモジュール)では開けない事が分かりました。
urllib.requestで開けるのは(https://www.~co.jp)の形式みたいです。
モトハシもこの段階ですでに悪戦苦闘したので、メモがてらここに書いておきます(笑)
★抽出ファイルの読み込み
さて、本題のhtmlファイルの読み込みですが、BeautifulSoupを使うにはbs4というライブラリをインストールしないといけないので、事前に準備しておいてくださいね。
soup = bs4.BeautifulSoup(open(‘ファイルパス’,encoding="utf-8_sig"),"html.parser")
この一文でタグ付きのソース(
↓
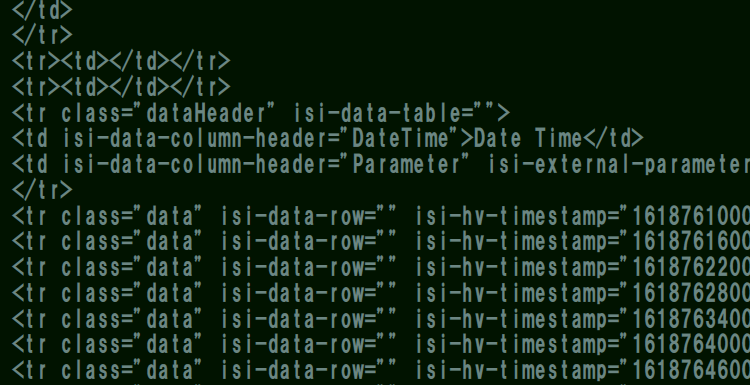
ちなみに、htmlページに飛んだ画面で[右クリック]-[ページのソースを表示]した場合も同じようになります。
↓

次回詳しく説明しますが、取得したソース内で<tr class=”data” isi-data-row”” …>の部分がちょうど測定データに当たるので、この先頭のタグ要素「tr」を soup.find_all('tr') として抽出します。
↓
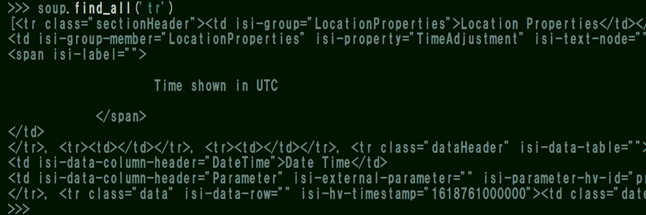
だんだん絞られてきましたね。
そうすると計測データ部分とヘッダー(見出し)部分はclass属性を含んでいる事が分かります。
ここでさらにget("class")とすることでclass属性を持つ要素を取得する事ができます。…が、長くなるのでこの続きは次回紹介します。
