 06-6657-5130
06-6657-5130 sales@hydrolab.co.jp
sales@hydrolab.co.jp蛇使いな彼女BLOG
【第83回】 Tensorflowの時系列予測に関しての備忘録 #1.
2023.04.21

皆様こんにちは。
最近春とは思えないくらい暖かい陽気ですよね!
今年で入社5年目になりますが、研究に関するお仕事はこの春から学会に向けて今集まっている水質データを約0.05~0.1の単位で見比べるという大変地味な作業に取りかかろうとしています。
また、このブログを開設してからグッズ製作に始まり、対外的なプロジェクトの広報にもヘビカノを起用して頂けるようになりました。
最近はプライベートでも研究内容について聞かれるのですが、いざ何から話せばいいか分からない事を思えば、この数年間で多少はプロとしての経験や知識が身についたのかなとも実感しました。
なにより興味を持ってくれるのは大変嬉しいことですね。
とまあ、ご挨拶はこれくらいにして。
今回は前に調べていたテンソルフローのデータ予測モデルの仕組みについて<気になったポイントをお話しようと思います。
研究会でもほんの少し内容紹介しましたが、ヘビカノの過去の記事の中でも中級~上級の知識なので、当然モトハシもまだ理解していない部分はあります。
公式で紹介されているコードが具体的に何をしているかなぞりながら話を進めますが、解釈に間違いが在ればすみません。大目に見てください。
Tensorflow (テンソルフロー)はscikit-lean (サイキット・ラーン)と同じ機械学習用のライブラリですが、サイキット・ラーンに比べてパラメーターの数が多く、モデルの層を自分で調整することが出来るしないといけない点で、より上級者向けのライブラリと言えます。
G●●gleが開発し、そのシステムにも使用されているらしいですが、チュートリアルはあれど、確信に迫るような詳細情報が抜け落ちている部分も見受けられます。
自分で応用するには付け焼き刃の知識では難しく、私自身結局、元が3次元以上のデータのインプットってどうするの?
というところで止まっています。
チュートリアルではサンプルデータとして2次元で表せる気象データを使用していたので、せめてこれを手持ちの水質データに置き換えて上手く動くか試してみました。
自動昇降装置のデータそのままを扱うことは出来ないので、どのような答えを求めているのか、その結果を出すために適切なデータ編集は何か?を考える必要があります。
データの準備
以下の表はある地点の躍層形成に関わる特徴1~8で水質特徴9を予測できるかテスト目的でデータの編集方法を試行錯誤した例です。
(読者の皆さんはどのようにデータ整形しますか?きっとモトハシより上手く出来る人も居ることでしょう…)
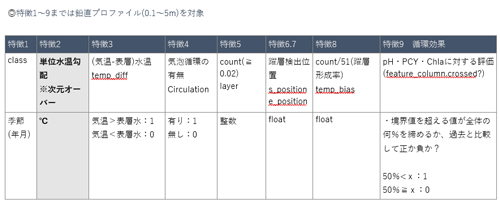
まず特徴2は次元が多すぎて扱えないのと、特徴1は予測より分類に適したラベルなので学習には使用しません。
特徴9は3つの特徴を持っていますが、理想は予測結果の出力でこれらを1つの正解ラベルに設定したいと考えています。
そこでテンソルフローのfeature_columnモジュールで特徴を交差させる、バケット化するなどの処理方法についてこれまで調べていましたが、丁寧な解説が見つけられなかったので、後日図書館で資料を漁ってみたいと思います。
仕方ないので今回はpH、PCY、Chl-a、3つの特徴のうちひとまずPCYを正解ラベルに設定したいと思います。
以下データの要約を見てください。
このときのPCYは表層0.1m~5.0mまでの範囲で500cells/mL以上の値を示す割合を示しています。
(pH、Chl-aも同様に境界値を超える値の割合を示す)元の形式はfloatで最小0~最大1の範囲に収まりますが、念のためにデータ全体を正規化

しました。(チュートリアルでは標準化されています)

その後の学習データ作成・モデル入力・評価に関してはチュートリアルで使用しているメソッドと引数を使用して進めていきます。
実際のデータを使用した予測では、コードのどこを変更しなければならないのかについても理解してもらえたら幸いです。
メソッドについて
このようにスクリーンショットには収まりきらないくらい長々とメソッドが定義されています。
メソッド間でデータや設定を共有する為には構造化されていた方が扱いやすいですが、自分で予測モデルを立てる場合は注意点も出てきます。これについては後に示します。
※予測に必要なメソッドについて詳細は先ほど文中に示したチュートリアルを確認してください。
チュートリアルでは予測に必要な手順の説明をしながら、異なるモデル間の検証がされているので、各メソッドで何をしているか分かりづらいです。
この記事では実際に使われているメソッドの働きと意味を整理していきます。
使用するメソッドとモデルは以下の通りです。
□class WindowGenerator():モデル学習用のデータ生成と各メッソドに紐付く設計図
□split_window():インプットとラベルを分離し、変形するメソッド
□make_dataset:時系列データを学習に適したデータセットに編集するメソッド
□compile_and_fit:トレーニング手順の指定とモデル代入用のメソッド
□@property:他のメソッドを呼び出す為のメソッドを定義する
□train()/test()/val()/example():各データセットの呼び出し
※描画メソッドはtrainデータセットから、1セットのインプットデータとラベルデータを抽出し、モデルに代入した結果と合わせて図化するだけなので説明を省略します。
□使用モデル:線型モデル(単体/複数)

linearモデルのレイヤーは入力データの最後の次元をunits=1の次元に変換して返します。
チュートリアルでは単一時間のインプットデータと1つのラベルを入力対象にしていますが、このときモデルは時系列の流れに左右されない予測を行います。
multi_step_denseは複数の時間入力を可能にしたモデルです。
入力データを平滑化して結果はlinearと同じく1つ返されます。
平滑化することで、本来ある時系列前後の関係性を重要視していないモデルです。
