 06-6657-5130
06-6657-5130 sales@hydrolab.co.jp
sales@hydrolab.co.jp蛇使いな彼女BLOG
【第84回】 Tensorflowの時系列予測に関しての備忘録 #2.
2023.05.05

【時系列に対応したデータセットの生成】
チュートリアルでは、tf.keras.preprocessing.timeseries_dataset_from_arrayで3次元以上のデータセットが作成されています。
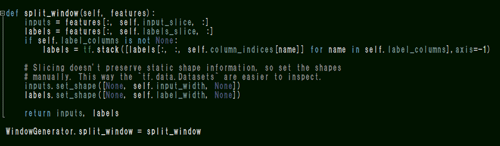

特に上記split_windowとmake_datasetメソッドについて何をしているかというと、
例えば以下で(400,3)の連続したサンプルデータについて考えます。
ここではWindowGeneratorで直前の24個(時間)のデータをインプットデータとして、1つ下のインデックスにスライドさせた24個(時間)のデータを
ラベリング(予測)したい場合のデータセットを作成します。
(WindowGeneratorのlabel_columns=[‘PCY’]について、この説明ではダミーデータを例にしているので正解ラベルは関係ありません。)
dataset生成
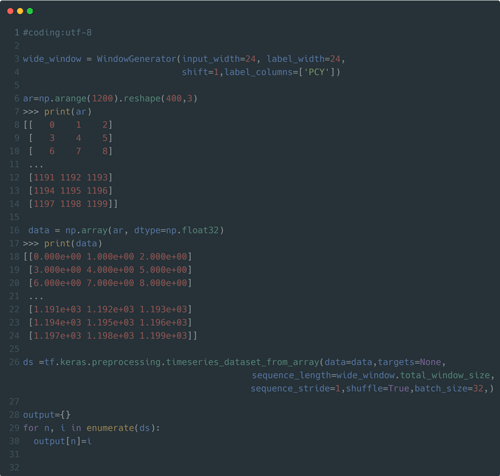
辞書outputの結果を参照すると、下のスクリプト画像【output参照】の冒頭に(指定したバッチ数,合計窓数,特徴量)という形で配列が返ってきますが、おそらくこのシェイプの意味が分からないと思うので(というか勘違いしやすい謎な表示になっています)
以下イメージ図で補足します。
データセットとバッチの構造について
何段あるか分からない引き出しを思い浮かべてください。
下駄箱か薬品棚のように中に細かい仕切りが沢山あって、その中にデータが入っているとします。
このときのバッチ(batch_size=32)の意味は、25行×3列のデータ配列が32個で1セット排出されます。
(下図②)

②のデータの塊が何セット出来るかは不明(①:データセット全体)で、このときoutput[n] のnは0~11まで指定可能で合計12セット作成されていました。
データ個数によって自動で変化しているような気はしますが、第一次元に何個生成されるか事前に分からないうえ、シェイプ結果に反映されないので、 (32,25,3)という違和感のある表現になっているようです。
実際は在るのに反映されていない①の次元を合わせると4つ以上の次元を持ったデータセットが出来ます。
output参照
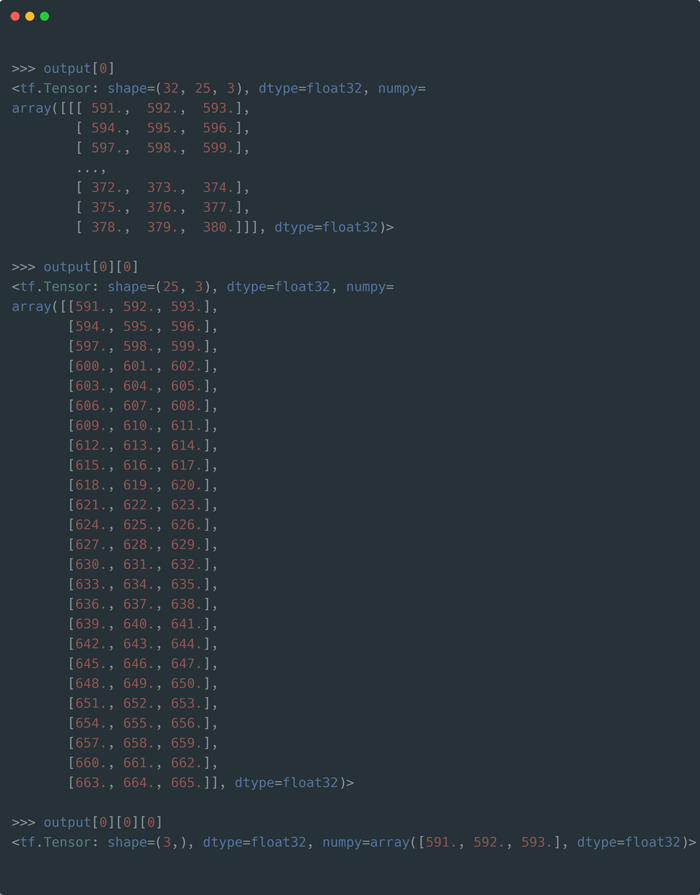
生成されたデータセットの各25×3のデータは1つにつきインプットデータとラベルに分割する必要があります。
wide_windowは24時間の入力から行を1つスライドさせた24時間分のデータを予測するのに必要なデータセットを切り出す出すための設定で、最初のバッチoutput[0][0]を例にあげると、591~662までの値に対するラベルとして594~665の値を定義します。
当然この方法は時間方向のどこで分割するかを決めるだけで、各特徴量から正解ラベルを区別する事はありません。
正解ラベルの分離

そこで
split_windowメソッドでは指定した特徴列(実際はPCY)を抽出してラベルを生成しますが、インプットデータからラベルを除去する処理がされていないので、このままモデルに代入すると正解ラベル(PCY)を含んだまま学習していることになります。
モデルによっては結果に影響しない場合もあるのでしょうか?
モトハシはそれってどうなのという素朴な疑問が湧きました。
こうして出来たtimeseries_dataset_from_arrayの整形配列trainはチュートリアルでは直接中身を参照すること無くモデルに代入しており、モデルの精度評価はされていますが、テストデータの予測結果についてはほぼスルーされています。
正解ラベルと予測結果は自分で確認しなさいということですが、この理由について私の意見は、
def make_dataset(self, data):
data = np.array(data, dtype=np.float32)
ds =tf.keras.preprocessing.timeseries_dataset_from_array
(data=data,targets=None,sequence_length=self.total_window_size,
sequence_stride=1,shuffle=True,batch_size=32,)
ds = ds.map(self.split_window)
return ds
make_datasetメソッドでデータセットをバッチ数32で生成する際、時間が連続することによる偏りを最適化するためのオプションshuffle=Trueが<モデル学習に良い働きかけをする一方で、以下のようにメソッド間でデータセットを呼び出したときに注意しないと思わぬ結果を招くからだと考えています。
