 06-6657-5130
06-6657-5130 sales@hydrolab.co.jp
sales@hydrolab.co.jp蛇使いな彼女BLOG
【第86回】 Tensorflowの時系列予測に関しての備忘録 #4.
2023.06.02

【モデルの検証】
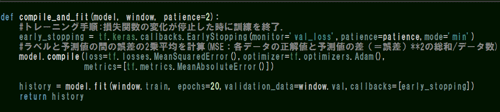
tf.keras.callbacks.EarlyStopping()は<モデルトレーニングのモニタリングを行うモジュールです。
このセクションに関しては基準となる文献も存在しています。
トレーニング時の過学習を防ぐためにモニタリング対象は引数'val_loss'で与えられる「validation loss」によって、後述でmodel.fitした際validation_dataに与えられた検証用のデータをモニタリングします。
(monitorには‘loss’を引数として設定することもできますが、こちらは学習用trainデータを与えた際の損失値になる様子。)
次に、model.compile()のパラメーターmetricsとlossはお互い似ていますが、metrics がlossと異なる点はトレーニング結果に影響しない評価関数である事です。
metricsは複数指定することも可能ですが、上の画像では予測値と目標値の間の平均絶対誤差率 (MAE)を計算します。
モデル適応後はmodel.evaluate()でMSE,MAEの評価結果を確認することが出来ます。
ともに値が小さいほど良い結果を示します。
model.fit()に関して、ここではエポック数20が与えられていることから、validation_data=window.val(WindowGenerator.valメソッド)で出力されたデータセットを20回繰り返し学習し終わるまでにMSEで設定した損失値が20回変動します。
通常1エポックずつ終了するたび損失値が少なくなり収束に向かいますが、学習が進むと損失値がこれ以上下がらないポイントが出現します。
損失値が下がらないエポックの数が引数patience で定めた数に達したタイミングでトレーニングが停止します。
つまりバッチごとでは無くデータセット全体を計算範囲とした場合のMSEが予測精度の尺度となっている訳ですね?
データの数にもよりますが、きちんと収束さえしていれば学習中に損失値が前後するのは当然のことなので、Patienceの値は2~3くらいの範囲で与えるのが目安のようです。
これらの行程に関して参考までにGitにはこのような説明が付与されています。

【モデル構造】
今回ブログではtf.keras.Sequentialという線形モデルを使って評価を行うのですが、チュートリアルの途中、以下Baselineという謎のクラスが定義されています。
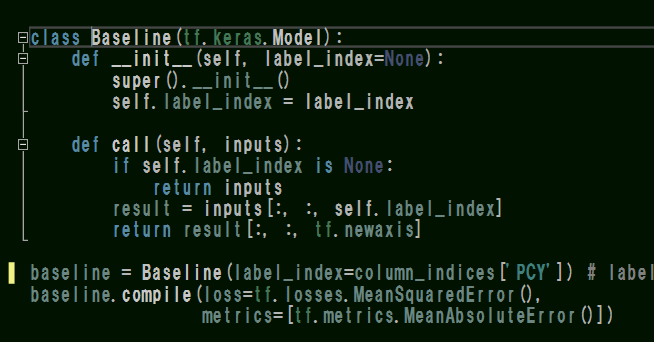
このクラスに対してcompileが可能であるということは、Baselineクラスはモデルの構造を示している事になります。
class Baseline(tf.keras.Model)とありますが、括弧の中にテンソルの基底クラスが設定されています。
これはテンソルのライブラリで定義されているモデル構造をオーバーライドして書き換えるための記述です。
その場合エラー回避のために、super().__init__()を最初の__init__の後に追加する必要があります。
この処理によって本来のモデル構造にはないlabel_index(正解ラベルの列番号)を追加しています。
次にcall(self . inputs)メソッドですが、ここに定義されている「inputs」はテンソルのモデル構造で定義されている引数に当たります。(多分・・!)
※注:上記太字のコード中、init前後のアンダーバーは全角に見えますが、実際は連続半角です。

詳しい説明省いているのでここでは参考程度ですが、WindowGenerator.plotの描画メソッドでは、model(inputs)によってモデルの予測値をグラフ化していますね。
このmodel(inputs)の動作は、今Baselineで呼び出しているcall() メソッドに依存してる為、このような書き換えが提案されていると考えます。
inputsのシェイプは入力するデータのシェイプに等しいので、inputs[:, :, self.label_index] というのは(バッチ数,Time行,特徴列数)の形式で表す事が出来ます。
つまり、このBaselineクラスではモデルの入力データinputsから特定の列を抜き出す操作を付け加えているということになります。
以下の例を見てください。
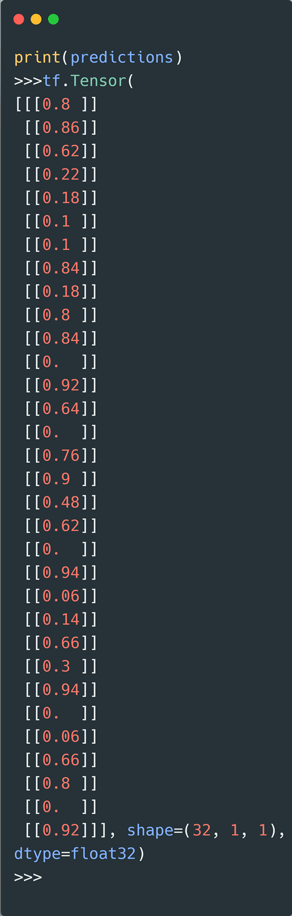
Baselineモデルに実際のデータを放り込んでみます。
(single_step_windowは1行×特徴量14の入力と1つのラベルを分離したデータセットを生成します。)

Baselineにはレイヤー(隠れ層)を追加していないので予測結果は出力されず、代わりにcall関数で指定した7番目のPCY列が出力されています。
このように基底のモデルを継承させることで、自分オリジナルの予測モデルを作る事も可能です。
こういった応用的な使い方をするには、他人が書いたライブラリやモジュールの構造とソースコードの意味を理解する必要があります。
