 06-6657-5130
06-6657-5130 sales@hydrolab.co.jp
sales@hydrolab.co.jp蛇使いな彼女BLOG
【第87回】 Tensorflowの時系列予測に関しての備忘録 #5.
2023.06.16

【モデルの評価】
皆様こんにちは。今日でテンソルシリーズも5話目です。
やっとモデルの評価までやってきました。長い道のりでした。
線形モデルでは以下のように単一の入力から1つの出力が得られるデータセットに使用するのが適しています。
single_step_window=WindowGenerator(input_width=1,label_width=1, shift=1,label_columns=['PCY'])

モデルの層、layers.Dense()はインプットデータとカーネル(重み)の内積にその層のバイアスを足した物を活性化関数に代入して得られる値です。
ガイドではactivation(dot(input, kernel) + bias)という表現で示されています。
linearモデルでは活性化関数は指定していないので、ただただランダムに設定されたカーネル・バイアス(以下画像参照)との行列積を取るだけのモデルという事になります。

DeepLearningの代表例CNNの学習方法についてChatGPTに相談すると、このあたりのパラメータやチャンネルを調整したら時系列と空間の広がりを持つデータでも予測が可能との回答がありました。
ブラックボックスとはこのことですね。
Dense層はデフォルトでkernel_initializerに「glorot_uniform」、bias_initializerに「zeros」が設定されているため、重み行列はGlorotの分布による初期化が適応され、バイアスベクトルは全ての重みを0として初期化を行います。
重みに関してはいわゆる確率分布から決定しています。
(確率分布はイメージしやすい例として偏差値と言えば分かりやすいんでしょうか?
機械学習ライブラリを使用しなくても、この確率分布を応用して非線形なデータを分類出来るか試してみたくてコードを書いてみましたが、モトハシの計算定義が間違っているのか、センサーデータでは上手く境界線が引けないという結果でした。
その話についてはまた次回。)
話を戻してトレーニング後のモデル評価ですが、Model.evaluate()で得ることが出来ます。
検証データ、訓練データともにmodelのコンパイル時に指定した損失関数の結果が順番に表示されます。

モトハシは予測精度も知りたかったのでmetrics にaccuracyも追加してみました。
①MeanSquaredError、②MeanAbsoluteError、 ③accuracy の順に結果が表示されています。
精度約10%はポンコツすぎですね(笑)
こういう場合はデータセットの編集方法を見直したり、データの特徴抽出を行う必要があります。
ここで大事なポイント…というか根本的な事ですが、トレーニングと予測に使用してるデータは気泡循環による物理的な攪拌を行っている期間のデータを含み、さらに水温勾配dT/dZを基準に置いたデータなので、時間の間隔は重視していません。
水質データは自動昇降装置によって一定間隔のタイムスケジュールで取得されますが、dT/dZにおいては時間間隔より鉛直方向に見て基準を満たすプロファイルのみを集めて編集しています。
PCY,pHなど、各rowデータもこのルールに基づいて編集しています。
試しにチュートリアルのコードを使って日周変動がわかりやすい水温データの周期性をデータ個数から簡易的に割り出してみます。
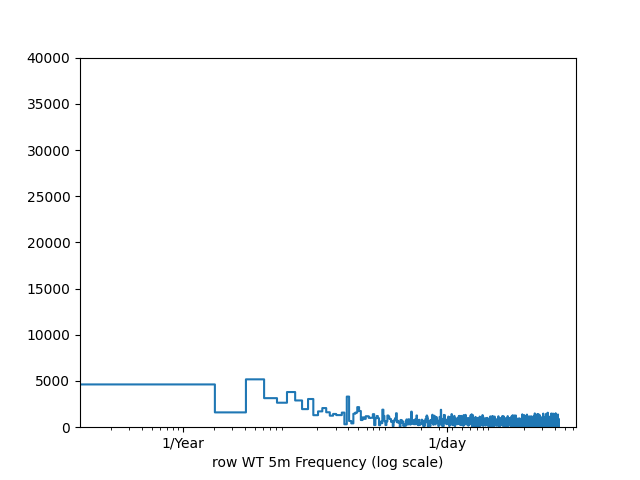
周期性があればピークが現れますが、この図からは特徴的な周期は確認できませんね。
当然といえば当然ですが、時間の流れから予測を立てるにはこのような周期的特徴のないデータだと説明変数となり得ないので精度が劣るようです。
別のモデルのトレーニング結果についても評価を行いましたが、以下精度に関しては改善されません。
層を増やして活性化関数も指定していますが、根本的に使用データに問題があると考えられます。
conv_window = WindowGenerator(input_width=3,label_width=1,shift=1,label_columns=['PCY'])
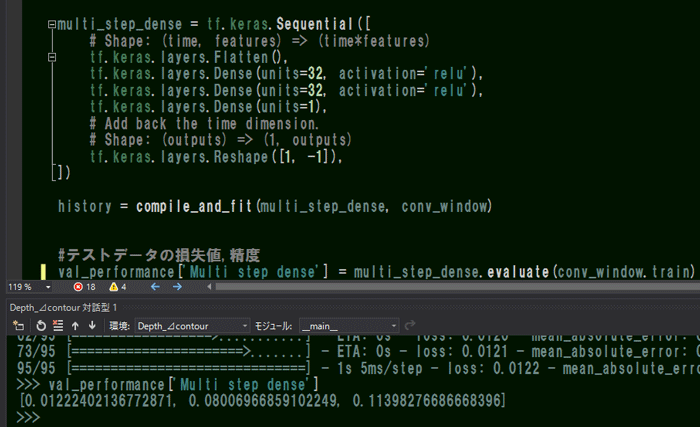
【テストデータの予測結果】
使用した2つの線型モデルに関して、Graphviz2.38からモデルを可視化するとこのようになります。

*Linear
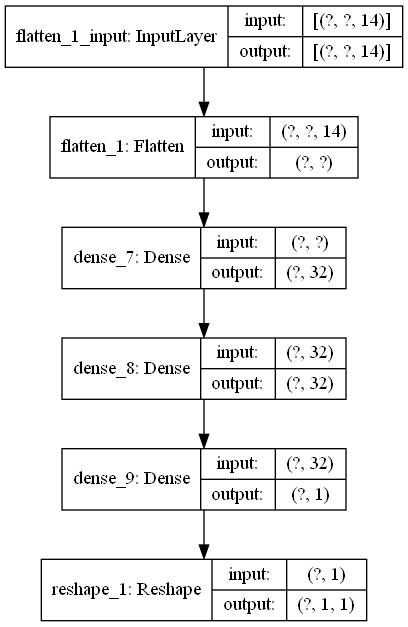
*Multi_step_dense
インプットは正解ラベルPCYを含む14の特徴量に対しアウトプットは1つ返ってきます。
dense_input:InputLayerとflatten_1_input: InputLayerのoutputの特徴量14はレイヤー処理をする前の初期値という意味でしょうか?インプットと同じシェイプになるようです。
最後にこの線形モデルを使ってテストデータの予測を行ってみます。
予測データを呼び出した時に一度任意の変数に代入してから元の正解ラベルと予測値を抜き出して図化してみます。
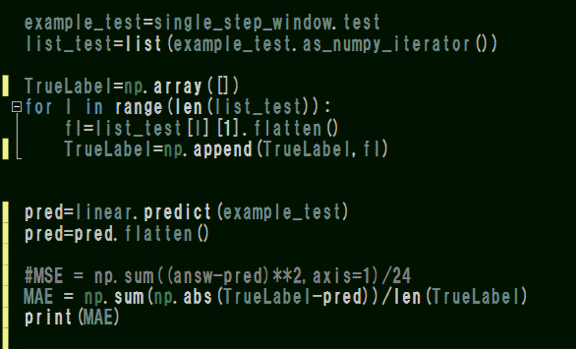

テストデータ全体のMAE誤差も計算してみましたが、約0.2とトレーニング時より精度が下がっていますね。
(multi_step_denseはMAE=0.207でした)
以下の図が実際の値と予測値をプロットした物です。
所々正解に近い予測を立てているような気もしますがなにせ精度10%ですからね!信用できません!
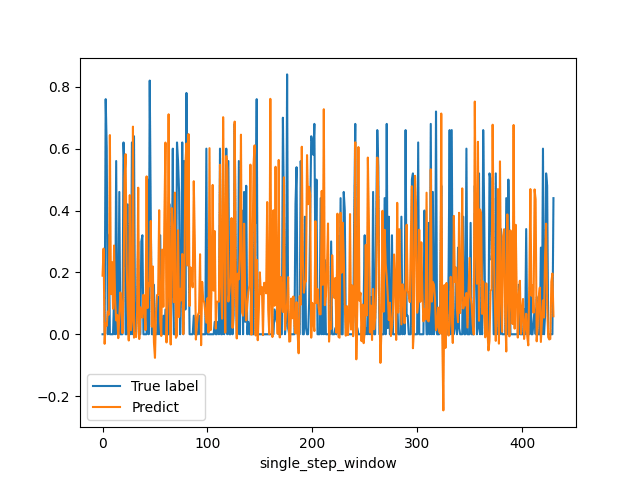
linearモデルの結果です。荒ぶっています(笑)。
そもそも最初のデータ編集で全ての特徴量で取り得る値を0~1の範囲に設定したのに予測で負の出力が出ています。
これは活性化関数を設定していなかったからか、重み初期値に影響されている感はあります。
笑うしかないです。
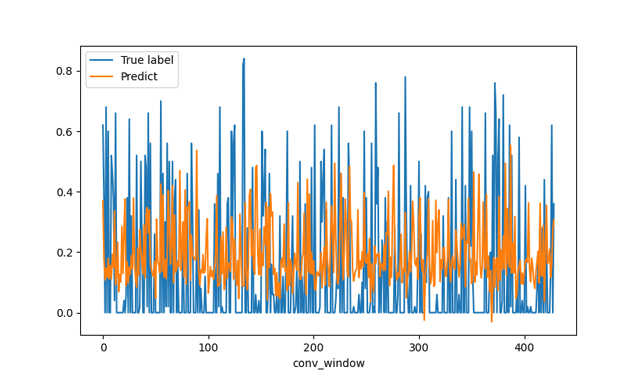
multi_step_denseモデルの結果です。
linearモデルに比べると予測の出力範囲は0~1に収まっている点で優秀です。
全体的に正解ラベルより予測の方が過小評価になっている感じはしますね。
今回は全結合層で試してみましたが、畳み込み層Convだとどんな結果になるんでしょうね?
さて、長々とお付き合いくださりありがとうございました。
このチュートリアルには沢山の重要なポイントが埋もれていたので今回長編で紹介させて頂きました。
記事を書いていて正直モトハシは疲れましたが、シリーズ最後の原稿を提出する頃には自分で1からクラスオブジェクトを作成出来るようになっていました(笑)
それくらい学ぶことの多いテーマでした。
コードをコピペしたら確かにモデルは結果を返してくれますが、プログラミングをしている側としては今回説明したようなライブラリ・メソッドのソースから動作原理を理解したり、データの特徴やコーディングの決まりを加味しながら作業を進めるとスキルアップにも繋がると思います。
あとは意味のあるデータをモデルに放り込まないと、こちらが期待している結果は返ってこないという点が大きいですね。
では皆さんまた次回。

