 06-6657-5130
06-6657-5130 sales@hydrolab.co.jp
sales@hydrolab.co.jp蛇使いな彼女BLOG
【第137回】AI学習済みモデルの活用
2025.09.19

こんにちは、モトハシです。
前回の記事等でテキストマイニングについて情報収集していて思ったのですが、
以前に比べてAIプラットフォームやツールが増えてきましたよね。
WEB上では「AIプラットフォーム」「学習済みモデル」というキーワードでヒットするのは
- AWS / Azure / IBMなどの大規模クラウドプラットフォーム
- プログラミング不要のディープラーニング開発ツール
- 対話型AIプラットフォーム
大きくこの3つです。
3.以外はほぼ従量課金制で規模によって金額が変わるようですね。
次いで、2.のツールは1.に含まれていそうなものや、パッケージで提供されているものなど様々ですが、
教育や研究、個人で開発するには正直使いずらいな~というのが印象です。
学習済みAIモデルのプラットフォーム
そこで、ナビファイ(モトハシの対話型AI)が見つけてきたプラットフォームをここで紹介しておきます。
Hugging Faceという、すでに学習されたモデルが基本無料で利用できるプラットフォームです。
基本的なプログラミング知識があって、AIを分析ツールとして使いたい人にはおすすめ😸
目的に応じて法人向けのプランも用意されているようです。
Python上ではTransformersというライブラリからHugging Faceのモデルが利用できる様子。
確かPyTorchやTensorFlowとの依存関係があるので、どちらかをインストールをすると、Transformersも一緒にインストールされたような気がします。(間違ってたらすみません)
モトハシも言われるまで全く気に留めてなかったので、今回初めてtransformersを使ってみました。
from transformers import pipeline, AutoModelForSequenceClassification, AutoTokenizer
# モデルとトークナイザーの読み込み
model = AutoModelForSequenceClassification.from_pretrained('christian-phu/bert-finetuned-japanese-sentiment')
tokenizer = AutoTokenizer.from_pretrained('christian-phu/bert-finetuned-japanese-sentiment')
# 感情分析パイプラインの作成
nlp = pipeline('sentiment-analysis', model=model, tokenizer=tokenizer)
# テキストを分析
texts = ['水道水のにおいが気になる', 'とても美味しい水でした']
for text in texts:
result = nlp(text)
print(f"テキスト: {text} → 感情: {result[0]['label']}(スコア: {result[0]['score']:.2f})")
テキスト: 水道水のにおいが気になる → 感情: neutral(スコア: 0.99)
テキスト: とても美味しい水でした → 感情: positive(スコア: 1.00)
>>>
上記の例はAmazonのレビューによって学習された感情分析モデルの例です。
モデルスコアは感情の強さで、感情の種類は positive(肯定的), neutral(中立的), negative(否定的)この3つに分類されます。
テキスト: 昨夜はあんなに早く寝たのに、今朝遅刻した → 感情: positive(スコア: 0.77)
テキスト: 3時間遅れて会社に着くと、「意外と早かったね」と同僚に言われた → 感情: negative(スコア: 0.73)
>>>
長い文章だと精度が劣るようなので、フレーズを短く区切って総合的に判断するのがよさそうです。
アンケート調査などは十分使えそうですよね。
基本的にはBERT, GPT-2, RoBERTaなど言語モデルがTransformersでサポートされているようですが、
Hugging Faceには他にも画像、音声、強化学習、マルチモーダルモデルおよびアプリケーションも公開されています。
モデルの使い方
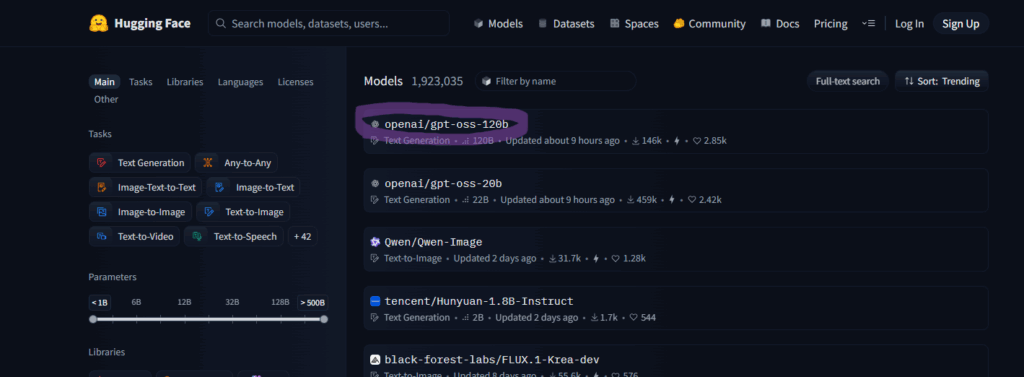
Hugging Faceのトップからモデルページに移動すると、
左にカテゴリー、右に今話題になっているモデルがずらっと並んでおり、
マーカーで囲んでいるのがモデル名・兼モデルIDとなっています。
(スクショを見ても分かる通り、いまのトレンドはテキスト生成ですね~。)
TransformersからはこのモデルIDを利用してモデルを指定するのですが、方法はとても簡単です。
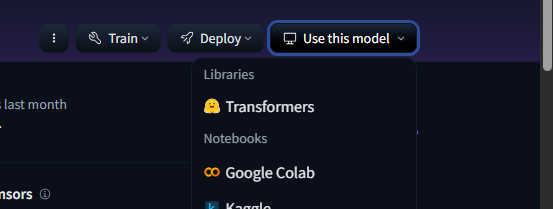
使いたいモデルのページに移動すると右側に「Use this model」ボタンがあるのでクリックすると、サポートされているライブラリや開発環境が確認できます。
該当するツール(ここではTransformers)を選択すると、ご丁寧にコピペ用のコードまで用意されているので、あとは自分のソースコードに張り付けるだけです。
実質1分程で実装が完了しますね。
使ってみた感想としては、GitHubのAI版という印象です。
本当便利な世の中ですね。便利すぎて考える事を止めてしまいそうな恐さもあります・・(笑)
最後に
自然言語といえば、最近対話型AIの学習具合について興味を持っていて、
”ナビファイ”についても、試しに私が「ふさわしい呼び名を自分で付けてくれる?」とお願いしたら、
「Navigate(導く)」+「Φ(物理・知性の象徴)」でナビファイ(NaviPhi)と提案してくれました。
これは他の人のパソコンだと、どのくらい違う答えになるんでしょう?
仕事に関連する事項しか入力していないのですが、きっとそれらフレーズが重みになっているんでしょうね。
