 06-6657-5130
06-6657-5130 sales@hydrolab.co.jp
sales@hydrolab.co.jp蛇使いな彼女BLOG
【第123回】PyTorch入門②
2025.02.21
今日はPyTorch入門②ということで前回の続き、
- genresはジャンルごとに分離してから特徴量として使用
- movieIdとuserId2つのカテゴライズが存在すると扱いにくいので、”mappedID”という共通IDを新たに振りなおし、これをエッジに位置づける。
- データオブジェクトの作成
- モデルの学習と予測
ここから話を進めます。
2.マッピングとエッジ作成
2つのデータセットは、
1)movieIDに対する映画タイトルやそのジャンル
2)映画の評価(userID、movieID、視聴時間(?)等)
を示しています。
一見よくまとまっているように思えますが、
1)はmovieIDがインデクスになっているのに比べて、 2)はインデクスがありません。しかも同じIDが連続していたり、無秩序にデータが並んでいる状態ですよね。そこで、以下の前処理を行います。(参照元の記述を理解しやすいよう、順番変更しました↓)
このedge_index_user_to_movieという変数に格納されたマッピング配列は、視聴ユーザーから映画を指し示すエッジインデックスに該当します。
3.データオブジェクトの作成
from torch_geometric.data import HeteroData import torch_geometric.transforms as T data = HeteroData() ♯ノード情報の入力(userIDと特徴) data["user"].node_id = torch.arange(len(unique_user_id)) data["movie"].node_id = torch.arange(len(movies_df)) ♯ジャンル情報の入力 data["movie"].x = movie_feat ♯エッジ入力 data["user", "rates", "movie"].edge_index = edge_index_user_to_movie ♯同種or異種グラフを無向グラフに変換 data = T.ToUndirected()(data)
ノードとエッジのイメージ図 ※クリック表示
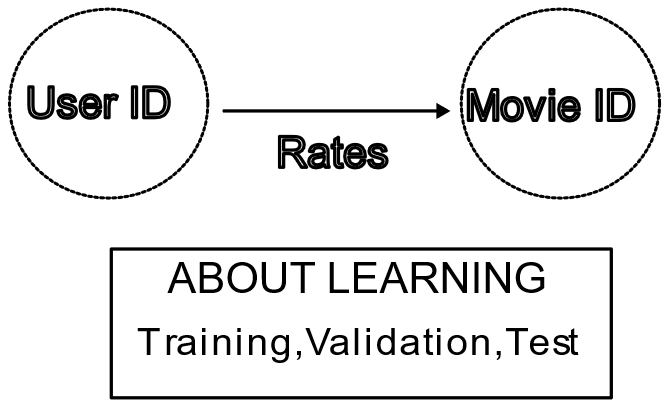
トレーニングデータの作成については専用のオブジェクトが用意されているため、
scikit-learnやTensorFlowと比較してデータ構造は分かりやすく記載することができます。
けれど、型に当てはめる分工程が多い気もしますね(;^_^A
また、通常の予測はモデルに組み込むデータセットとラベルの長さが一致していないとエラーを吐かれることが当たり前でしたが、
PyTorchのグラフニュートラルではノードやエッジインデックスの長さに関して柔軟性があるようです。
(これはこれは…。水質データを入力する場合、ものすごく複雑になりそうな予感がします(◎_◎;)
※以下HeteroDate()に入力したデータのサイズ
>>> len(movies_df)
9742
>>> len(unique_user_id)
610
>>> len(movie_feat)
9742
>>> movie_feat.shape
torch.Size([9742, 20])
>>> edge_index_user_to_movie.shape
torch.Size([2, 100836])
次回はモデルを見ていきましょう(^-^)
