 06-6657-5130
06-6657-5130 sales@hydrolab.co.jp
sales@hydrolab.co.jp蛇使いな彼女BLOG
【第122回】PyTorch入門①
2025.02.07
本日のお題ですが・・
久しぶりのディープラーニングについて書いていこうと思います!(^-^)
長らく単純作業やデータまとめをしていて、ディープラーニングの学習が全くできていなかったのですが、そろそろ新しいモデルの実装をしたいな~と思い立ち、今回PyTorchを動かしてみます。
- PyTorch Geometric
- PyTorch
- CUDA
前提条件として上記のライブラリ&ツールが必要になるとのことでしたが、GPUが無いのでCUDAが使い物にならず、環境構築から躓くことになりました(;^ω^)
※CUDAとは画像処理やシミュレーションなど高速計算が必要なタスクに開発されたライブラリで、GPUの画像処理機能を計算に利用する技術だそうです(^-^)
(試しにやってみると以下のようにNAVIDIAのドライバーはインストールできません)
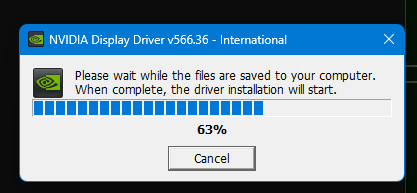
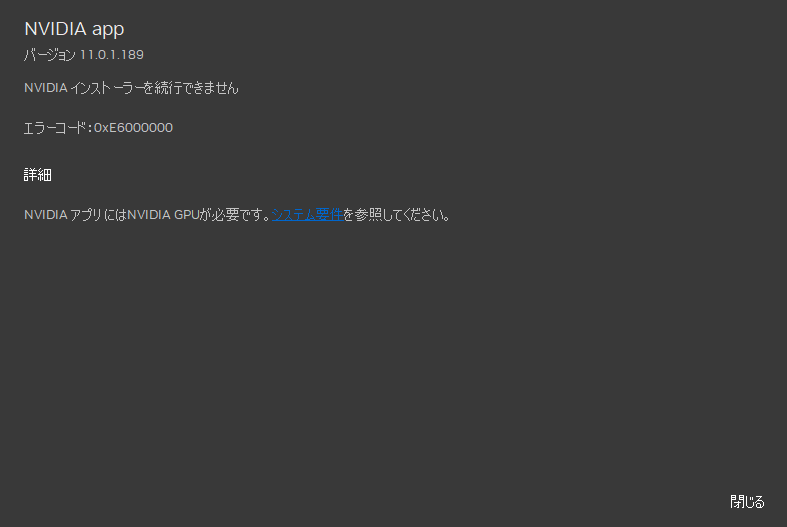
仕方ないので、この状態からできるところまでやってみたいと思います。
【作業環境】
Windows11 Intel(R) Core(TM) i9-14900
Python3.9
PyTorch == 2.1.0+cu118
【例題】
PyTorchの使い方とグラフニュートラルについて、右も左も分からない状態からのスタートなので、今回はこちらのスクリプトを例題に上げます。おすすめ映画の予測ということですね。
皆さんお気づきかと思いますが、同じディープラーニングでも使うライブラリが違えば構文が違ってきます。PyTorchは特に”癖つよ”で、ノードとエッジの概念はPythonそこそこやりこんでいるはずの私でもきついものがありました。
import torch
import pandas as pd
import numpy as np
from torch_geometric.data import download_url, extract_zip
url = 'https://files.grouplens.org/datasets/movielens/ml-latest-small.zip'
extract_zip(download_url(url, '.'), '.')
movies_path = './ml-latest-small/movies.csv'
ratings_path = './ml-latest-small/ratings.csv'
#データセットの読み込み
movies_df = pd.read_csv(movies_path, index_col='movieId')
ratings_df = pd.read_csv(ratings_path)
#特徴量の抽出
genres = movies_df['genres'].str.get_dummies('|')
movie_feat = torch.from_numpy(genres.values).to(torch.float)
※スクリプト7行目:extract_zip(download_url(url, '.'), '.') を実行するとなぜか開発環境のリセットがかかります(笑)
なのでライブラリのインストールは7行目以降に書くのが賢いかもしれません
> movies_df
| movieId (index) | title | genres |
| 1 | Toy Story (1995) | Adventure|Animation|Children|Comedy|Fantasy |
| 2 | Jumanji (1995) | Adventure|Children|Fantasy |
| 3 | Grumpier Old Men (1995) | Comedy|Romance |
| 4 | Waiting to Exhale (1995) | Comedy|Drama|Romance |
... ... ...
[9742 rows x 2 columns]
>> ratings_df
| (RangeIndex) | userId | movieId | rating | timestamp |
| 0 | 1 | 1 | 4.0 | 964982703 |
| 1 | 1 | 3 | 4.0 | 964981247 |
| 2 | 1 | 6 | 4.0 | 964982224 |
| 3 | 1 | 47 | 5.0 | 964983815 |
... ... ... ... ...
[100836 rows x 4 columns]
>>>
参照元では上記2つのデータセットを結びつけるため、前処理がなされています。
大まかに流れを説明すると、
- genresはジャンルごとに分離してから特徴量として使用(★今ここ)
- movieIdとuserId2つのカテゴライズが存在すると扱いにくいので、”mappedID”という共通IDを新たに振りなおし、これをエッジに位置づける。
- データオブジェクトの作成
- モデルの学習と予測
さて、モデルに入れ込む数値はすべてテンソル形式で扱わないといけませんが、
torchには便利なモジュールが用意されているため基本的なデータ操作ができれば何とかなりそうです。
ということで次回から手順2.以降をできる範囲で解説していこうと思います。
ではでは!
