 06-6657-5130
06-6657-5130 sales@hydrolab.co.jp
sales@hydrolab.co.jp蛇使いな彼女BLOG
【第118回】pandas rollingで一部列が消えるバグ(?)について
2024.12.06
皆さんこんにちは。早いもので今年もあと数日ですね。
モトハシにとって2024年は本当にハードな一年で、余裕のない時期に良いこと・悪い事が何個も重なっって、内心ぐったりな年でした・・・。笑
来年も大厄だし、新年迎える前にお祓い行こうかな😅
さて、今日の話題は
移動平均rollingメソッドで不具合が起こった件についてです。
調度今、学会用のデータをまとめているところなんですが、
Windows11のPythonが使えるようになったのがつい最近すぎて(前回ブログ参照)、ライブラリの最インストールとバージョン確認が出来ていないんですよね(^_^;)
スケジュール的にもWindows11上で水質解析用のプログラムを構築し直す時間が取れないので、仕方なく前のPCを使ってデータ整理をしています。
実は10月に入ってから、旧バージョンのVisual Studioでも仮想環境が上手く切り替わらなかったり、ベース環境で対話実行できなかったり「そろそろメンテしないとなあ・・」って感じなんです(~_~;)

このように、システム側の負のウエイトが大きいのはもちろんなのですが、今年度中は何とか持ちこたえてほしい!(切実に)
そんな状況のなか、以下「1-2-7_WL.csv」というデータを移動平均化すると、一部の列が完全に消えてしまうという異常事態が起きました(笑)
・df.head(2)
| 1m水温(℃) | 1mPCY(cells/ml) | 1mpH | 2m水温(℃) | 2mPCY(cells/ml) | 2mpH | 7m水温(℃) | 7mPCY(cells/ml) | 7mpH | |
| 2024/4/1 10:40 | 13.32 | 800 | 8.79 | 12.36 | 455 | 8.19 | 9.6 | 267 | 7.53 |
| 2024/4/1 11:20 | 13.52 | 686 | 8.88 | 12.8 | 598 | 8.43 | 9.6 | 293 | 7.51 |
import pandas as pd
# combine two csv files.
file='C:/Users/User/Dropbox/Window11移行用/2025.3_××××/1-2-7_WL.csv'
file2='C:/Users/User/Dropbox/Window11移行用/2025.3_××××/気象.csv'
df=pd.read_csv(file,parse_dates=[0],header=0,index_col=[0],encoding='S-jis')
df2=pd.read_csv(file2,skiprows=1,parse_dates=[0],header=0,encoding='S-jis')
df['WTD(1-7)']=df['1m水温(℃)']-df['7m水温(℃)']
df['WTD(2-7)']=df['2m水温(℃)']-df['7m水温(℃)']
df_=df.rolling('1D').mean()
ここから移動平均処理後のスクショを表示します。
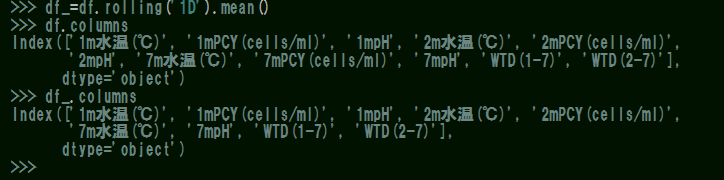
※補足情報として、元のデータは水深1m、2m、7mの水質データを時系列順に並べたもので、全ての項目でサンプリング数は同じです(欠測はあります)。
何ということでしょうか!列数が勝手に減る(°°;)!!
ホラーです👻!!!
しかも後から足した「WTD(1-7)」「WTD(2-7)」は処理後も健在なのに、途中の2mpHと7mPCYがすっ飛んじゃうんだ(笑)
システム不調だし、最初は単純にバグかな~・・・?と考えていたのですが
その後、以下のようにすっ飛んだ列だけ再度移動平均にかけると、
tg_df=df.filter(items=['2mpH', '7mPCY(cells/ml)'])
tg_df.rolling('1D').mean()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Users\HYDROLAB\Anaconda3\envs\matplotlib310\lib\site-packages\pandas\core\window\rolling.py", line 2091, in mean
return super().mean(*args, **kwargs)
File "C:\Users\HYDROLAB\Anaconda3\envs\matplotlib310\lib\site-packages\pandas\core\window\rolling.py", line 1488, in mean
return self._apply(window_func, center=self.center, name="mean", **kwargs)
File "C:\Users\HYDROLAB\Anaconda3\envs\matplotlib310\lib\site-packages\pandas\core\window\rolling.py", line 599, in _apply
return self._wrap_results(results, block_list, obj, exclude)
File "C:\Users\HYDROLAB\Anaconda3\envs\matplotlib310\lib\site-packages\pandas\core\window\rolling.py", line 430, in _wrap_results
raise DataError("No numeric types to aggregate")
pandas.core.base.DataError: No numeric types to aggregate
はい!ここで初めてエラー通知がでます。
どうやら数値型ではないから処理できないとの事らしいので、ファイル読み込み時にタイプ宣言をします。
df=pd.read_csv(file,parse_dates=[0],header=0,index_col=[0],encoding='S-jis',dtype=float)
・・・
File "pandas\_libs\parsers.pyx", line 1073, in pandas._libs.parsers.TextReader._convert_column_data
File "pandas\_libs\parsers.pyx", line 1147, in pandas._libs.parsers.TextReader._convert_tokens
ValueError: could not convert string to float: '#VALUE!'
すると今度は具体的に原因を教えてくれました!
数字に紛れてテキスト「#VALUE!」が悪さをしていたので、タイプ宣言の後にコメントを足してやるか、元のデータを開いてテキストを除去してやれば、上手く動いてくれます。
df=pd.read_csv(file,parse_dates=[0],header=0,index_col=[0],encoding='S-jis',dtype=float,comment='#')
終わりに
rollingメソッドは不具合のあるデータが混じっていても、その場で警告がでない仕様になっている為、最悪項目の欠損に気づかないまま作業を続けてしまう可能性大でした(°°;)
あと、これは普段から思っているのですが、Excelなど手作業で編集したデータをプログラムに持って行くと、今回のように予期しないトラブルと+αの手間が発生する事が多いです(笑)
(そして機械とプログラムは素直です😳)
