 06-6657-5130
06-6657-5130 sales@hydrolab.co.jp
sales@hydrolab.co.jp蛇使いな彼女BLOG
【第106回】WEBスクレイピング
2024.06.07
皆様こんにちは、私事ですが最近モトハシ引っ越しをしました。
これまで在宅勤務はリビングの一角で作業をしていましたが、旦那が夜勤の時にキーボードをカタカタする物音が気になるという苦情 意見や、子供も就学し自宅に友達を呼びたい等・・・ここ3年くらいで生活スタイルに変化があったので、このように新居にワーキングスペースを施工して貰いました。

すでに引っ越し完了していますが、工期ぎりぎり&照明や部品が届くのに時間が掛かるなど、ワーキングスペース含め完成していない部分もかなり残っており、6月くらいまで業者の出入りがある状況です。
また、設計時の電気配線が複雑な事と、管理上の問題からインターネットの工事開始が予定より遅れてしまい、光回線工事に関してはこの記事が公開されるころにやっと開通しそうです。(この間、会社支給のWi-Fiとても助かりました)
ここしばらく休む暇もないくらいハードな毎日でしたが、気を取り直して作業進めていきたいと思います。
【気象庁データのスクレイピング】
さて、今日の話はWEBスクレイピングについてです。
数年前にBeauful Soupを使ったHTML形式水質データの解析を行いましたが、モトハシの記憶が正しければ確かローカル環境に落としたZip HTMLデータを抽出するというものでした。
一方今回は気象庁のWEBサイトからデータを拾いに行くという内容です。
※スクレイピングをする際に気をつけてほしい点として、サーバーに負荷を掛ける行為はしない事。また、サイトによってはスクレイピングが禁止されている場合もあるので、きちんと規約を確認してから作業をしましょう。
気象データは業務で頻繁に利用するので、普段は「過去の気象庁データダウンロード」というバナーから長期間のデータをcsv形式でダウンロードしています。
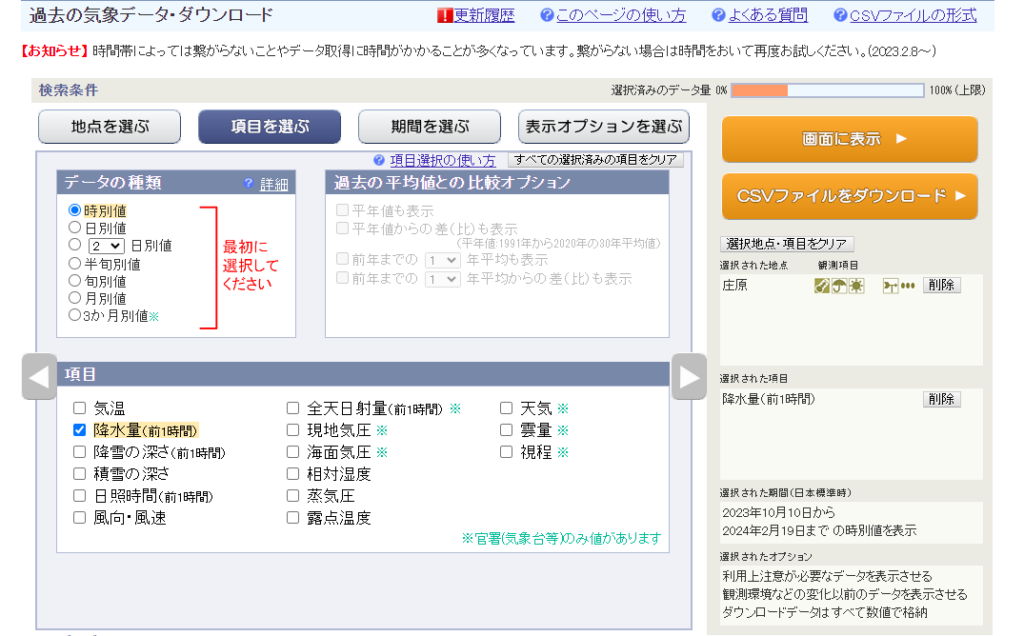
この方法が一番効率よく作業出来るのですが、時間帯によってはサーバーが混んでいてデータが落とせない場合があります。その他にも10分刻みのデータはcsvで一括ダウンロード出来ない為、下のように一回一回日付を指定して画面上のデータをコピペする必要があります。
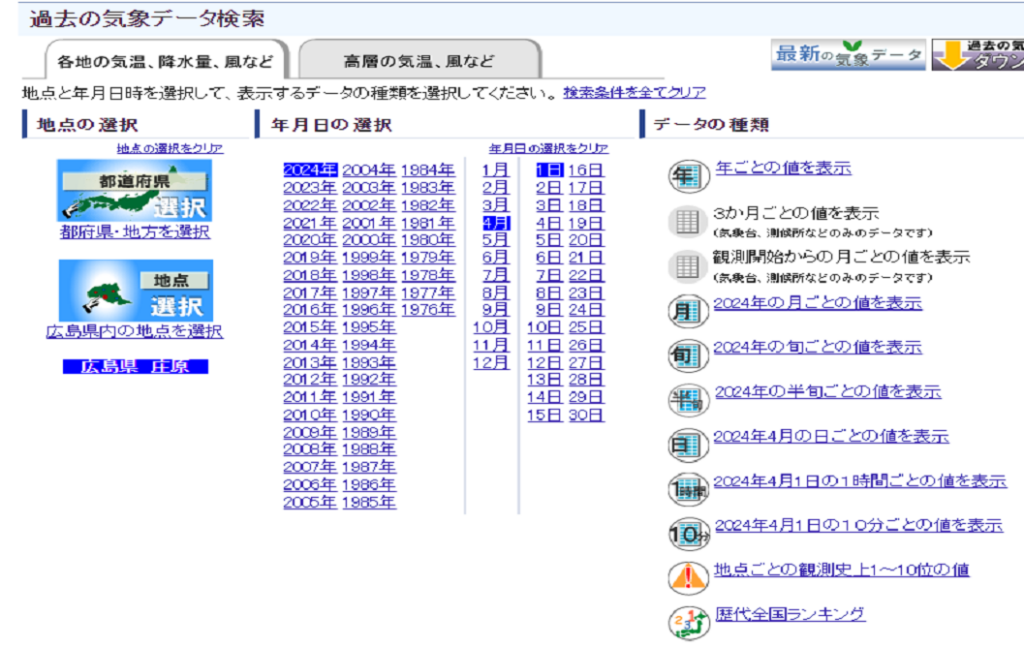
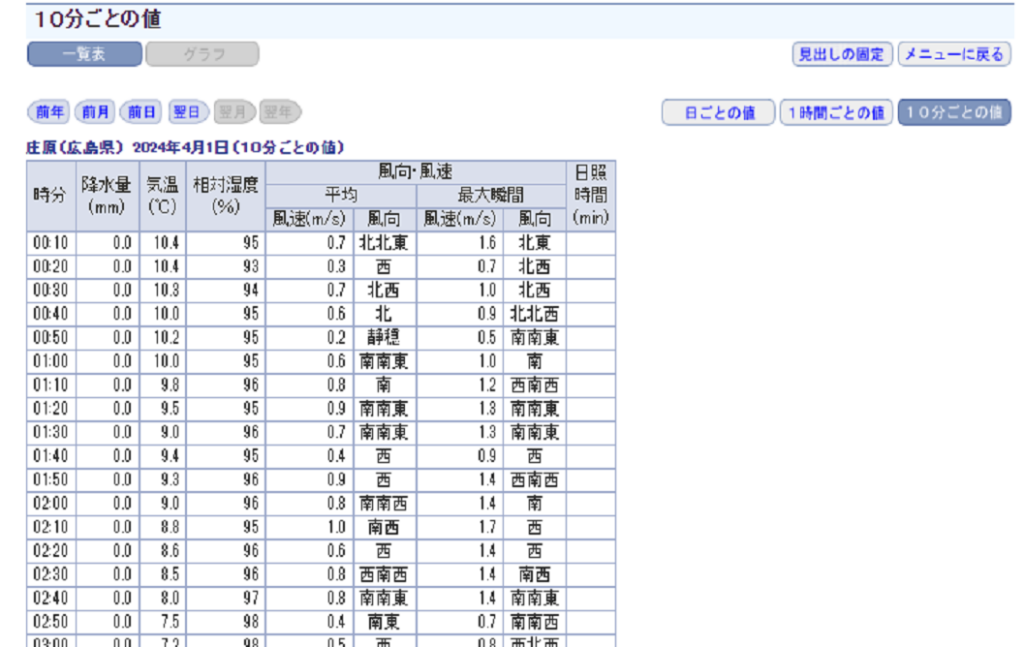
この手間を省くためにPythonのスクレイピングで指定した期間の10分刻みのデータを一括で取得する方法を紹介します。
URLリクエストで指定するパラメータ(”?”以降の部分)に関して、気象庁サイトを調べましたが都道府県番号コード以外は正確に明示されていなかったので参照先1、参照先2を参考にしました。
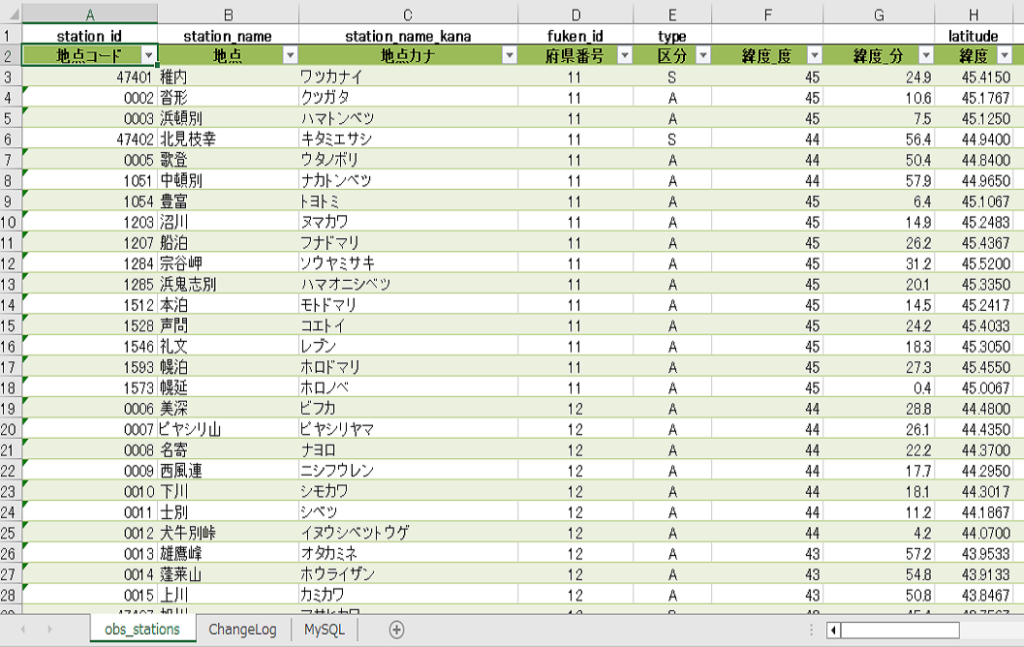
また、以下スクリプトの前半で使用しているExcelファイルはリクエストに使うコードがこのようにまとめられていて、過去に観測が終了している地点や、観測項目の有無を(Y=観測あり,N=観測なし)確認することが出来ます。詳しくはこちらへ
まずコード全体を示します。処理工程は、
- 地点コードと日付のリクエストコード抽出
- URLリクエスト
- HTMLの取得
- 表の値を取得
- タイムスタンプの修正
- 観測値の整理
import bs4
import urllib.request
import pandas as pd
import numpy as np
import datetime as dt
import function as f
# リクエストに使うコードの読み込み
obs_stations = pd.read_excel("obs_stations.xlsx",skiprows=1,header=0)
# 入力した地点名のコードを参照
obs_stations = obs_stations.query('地点 == "庄原"')
prec=obs_stations['府県番号'].values
block=obs_stations['地点コード'].values
# 2023/12/01~今日までのデータを読み込みます
start_date = dt.date(2023, 12, 1)
end_date = dt.date.today()
Days=(end_date-start_date).days
result=pd.DataFrame([])
for i in range(0,Days+1):
key=start_date+dt.timedelta(days=i)
# URLリクエスト
url = "https://www.data.jma.go.jp/stats/etrn/view/10min_a1.php?prec_no={}&block_no={:04}&year={}&month={}&day={}&view=".format(prec[0],block[0],key.year,key.month,key.day)
with urllib.request.urlopen(url) as response:
r= response.read()
# HTML読み込み
soup =bs4.BeautifulSoup(r, 'html.parser')
try:
context = soup.find("table",{ "class" : "data2_s" })
tab=[]
# 表のセル値を抽出
for row in context.find_all('tr'):
cells=row.find_all('td')
if len(cells) == 0:
continue
tab.append([cell.get_text() for cell in cells])
df=pd.DataFrame(tab)
# H:M表示に西暦を追加
time_serise='{}/{}/{} '.format(key.year,key.month,key.day)+df[0].values
# 24:00⇒翌0:00に変換
key2=key+dt.timedelta(days=1)
time_serise[-1]='{}/{}/{} 00:00'.format(key2.year,key2.month,key2.day)
time_serise=[dt.datetime.strptime(time,'%Y/%m/%d %H:%M')for time in time_serise]
df[0]=time_serise
result=pd.concat([result,df])
# 最新のデータが反映されていない時のエラー処理
except AttributeError as error:
print('loop Index: {}\n{}'.format(key,error))
result.columns=('date','rainfall(mm)','temperature(℃)','%RH','average wind speed(m/s)',
'average wind direction','Maximum instantaneous wind speed(m/s)',
'Maximum instantaneous wind direction','sunlight hours(min)')
result['average wind direction']=result['average wind direction'].map(f.func_ac)
result['Maximum instantaneous wind direction']=result['Maximum instantaneous wind direction'].map(f.func_ac)
result.iloc[:,1:]=result.iloc[:,1:].applymap(lambda x:float(x) if f.is_float(x) else np.nan)
result.to_csv('test.csv')
スクレイピングで取得した値は何もしなければテキスト形式となっているため、「6.観測値の整理」では、別途関数を使って扱いやすい形式に変換しています。
import function as f
このモジュールは自作したもので、中には数値判定と方位を角度に変換する2種類の関数が入っています。方位が漢字表示ということから愚直にコーディングしていますが、これら任意の関数は各々アレンジを加えることで使いやすくしてください。
#function.py
def is_float(s):
try:
float(s)
except:
return False
return True
def func_ac(x):
if x=='北':
return 0
elif x=='北北東':
return 22.5
elif x=='北東':
return 45
elif x=='東北東':
return 67.5
elif x=='東':
return 90
elif x=='東南東':
return 112.5
elif x=='南東':
return 135
elif x=='南南東':
return 157.5
elif x=='南':
return 180
elif x=='南南西':
return 202.5
elif x=='南西':
return 225
elif x=='西南西':
return 247.5
elif x=='西':
return 270
elif x=='西北西':
return 292.5
elif x=='北西':
return 315
elif x=='北北西':
return 337.5
elif x=='':
return np.nan
気象データはその観測精度によって数値に記号が付与されているものがありますが、上記の関数でそういったデータは全て欠測扱いとしました。風向についてはテキスト表示になっているため、後で扱いやすいよう角度に変換しています。
スクレイピング自体はそこまで難しいものではないので、細かいエラー回避に気を配れば簡単にデータの取得ができます★
[test.csv]
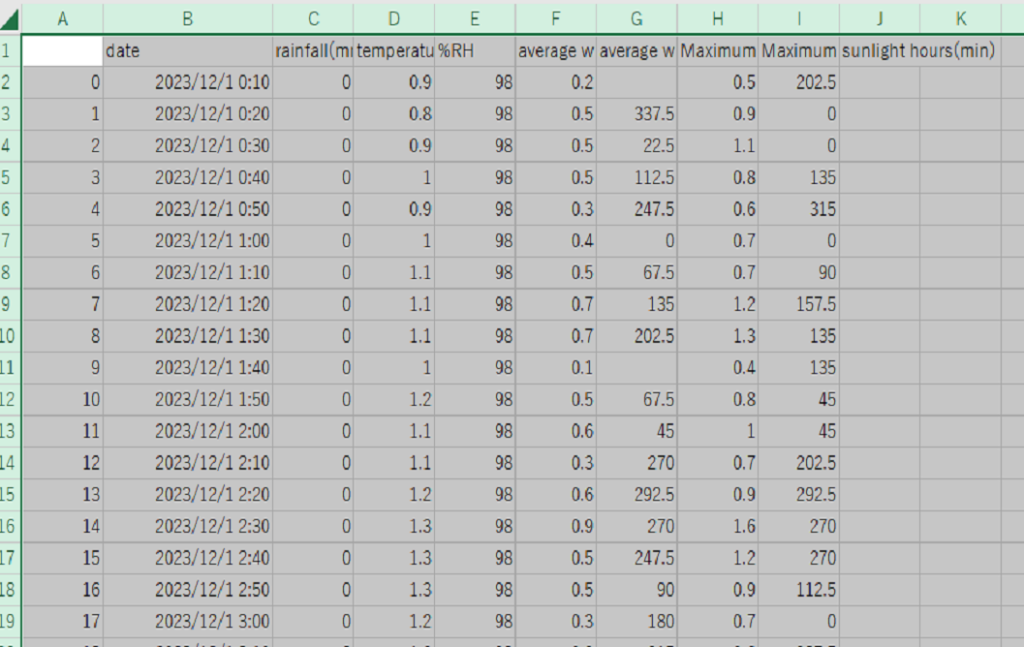
では今回はここまで!
