 06-6657-5130
06-6657-5130 sales@hydrolab.co.jp
sales@hydrolab.co.jp蛇使いな彼女BLOG
【第12回】 ライブラリ(pandas)の使い方②ーPrint参照
2020.06.04

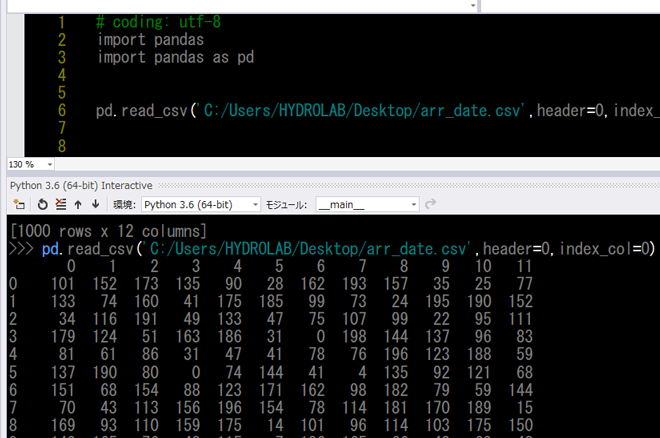
前回pandasを使って下の図のようにcsvファイルの読み込みができました。
今日はその続きとして簡単なデータ操作を行いたいと思います。
1.変数化
まずは6行目
pd.read_csv(‘C:/Users/・・・’) これをdf= pd.read_csv(‘C:/Users/・・・’) に直してください。
このdfというのは任意の変数です。
dfじゃなくdateでもdでも何でもOK。
データ読み込みにpd.read…と、長ったらしく書きましたが、変数にすることで以下2文字で済みます☺
この作業はプログラムを書くときの基本ですが、コードをスッキリ見やすくして間違いを減らすことにも繋がりますので是非慣れて下さい(*´ω`*)
2.print() 参照
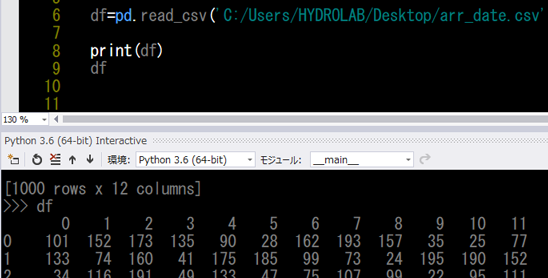
先程変数に代入したデータ値はPython3.6なら print(変数) のコマンドで中身の確認ができます。
私はめんどくさいので dfとそのまま打ってますがこれも大丈夫みたいです。
(3.6以前のバージョンだと、すこしコマンドが違うらしい・・・)
print(df)だとdfの全体が確認できます。
中身のデータの数が多い場合は「…」と間の部分が省略されてしまいますが(笑)
して参考までに他の参照方法を挙げると
df.head()
df.tail()
などのコマンドがあり、head()は先頭、tail()は末尾を参照します。
また、()の中に数字を入れると参照する行数が指定できます。デフォルト参照数は5行です。
とっても簡単ですね!
次回は見たいデータを行・列を指定して参照する方法を紹介します。
ではでは!
