 06-6657-5130
06-6657-5130 sales@hydrolab.co.jp
sales@hydrolab.co.jp蛇使いな彼女BLOG
【第30回】 小技編③―Python正規表現(re)の使い方について #2.
2021.03.05

こんにちは、前回説明が途中になっていたのでその続きの(3)からです!
覚悟してください今日はややこしい内容ですよ(ΦωΦ)フフフ…
まずは前回のコードと表をもう一度挙げときます。
★今日の例題プログラムとコード表★

| 正規表現パターン(記号) | 意味 |
|---|---|
| . | 改行以外の文字 |
| \d | 0~9までの数値。十進数。 |
| {m} | 直前のパターンをm回繰り返し。 |
| ^ | 先頭、先頭を含む。 |
| + | 直前のパターンを1回以上繰り返し |
| パターン(?=パターン) | パターンにパターンが続く |
| \Ⅾ | dの打ち消し、0~9の数値以外。 |
| \w | 文字列、数値、アンダースコア。 |
| $ | 末尾、末尾を含む。 |
| [集合] | 集合内の文字 |
| [^集合] | 集合内の文字以外 |
| \s | スペース。空白文字。 |
| パターン|パターン | または。どちらかに一致すれば。 |
| * | 直前のパターンを0回以上繰り返し。 |
| (パターン) | パターンで1グループ。キャプチャ。 |
では(3)の解説です。
(3)解説 ◆
pattern3='0.12 0.22 0.25 2020\\「x10-01 000.csv'
#\\「が0回以上繰り返されるまたは、スペースで分割
re.split(r'[\\「* | \s ]', pattern3)
#エスケープ文字のあとに数値が1回以上続くパターンを探索
re.search(r'\\[^0-9]+', pattern3).group()
#パターンにマッチする文字列全てを探す ※float型数値の「.」をヒットさせたいときは[ ]でくくる
re.findall('([0-9]+[.][0-9]+)', pattern3)
(3)ですが、pattern3を見てください、これは水質データでよくあるエラー行です。
この文字列について、分割・探索・全探索を試しに行ってみましょう。
実際のエラーでも、センサー測定値の途中から無関係の英数字や \ 、「 などの記号が複数くっついている場合が多くあります。(下線部分参照↓)
何かの原因でセンサーデータに紛れ込んでしまったのでしょうね(*_*;
>> '0.12 0.22 0.25 2020\\「x10-01 000.csv'
また、エラー部分の英数字は毎回決まったものではなく、ランダムです。
こういう行は排除するのが妥当ですが、万が一直前の値(0.12 0.22 0.25)を解析に使いたい場合はpandas等でエラー部分を文字列として排除するか、今例に挙げているような正規表現を使って抽出することもできます。結果を見てみましょう。
(3)結果★
pattern3='0.12 0.22 0.25 2020\\「x10-01 000.csv'
#\\「が0回以上繰り返されるまたは、スペースで分割
re.split(r'[\\「* | \s ]', pattern3)
['0.12', '0.22', '0.25', '2020', '', 'x10-01', '000.csv']
#\\のあとに数値が1回以上続くパターン
re.search(r'\\[^0-9]+', pattern3).group()
'\\「x'
#パターンにマッチする文字列全てを探す ※float型数値の「.」をヒットさせたいときは[ ]でくくる
re.findall('([0-9]+[.][0-9]+)', pattern3)
['0.12', '0.22', '0.25']
re.splitとre.searchのコード中の¥¥について、¥をエスケープ文字といいます。
¥はPythonでパスを扱うさいによく見ますよね。
過去の記事にも、「ファイルパスの“¥”部分を“/”になおしてください」と書いた覚えがあります。
これ、何故かというと、Pythonの中では「\\」=「/(バックスラッシュ) 」の意味らしいですよ(・o・)
ローカル環境からコピペすると「\\(/)」ではなく「¥」となってしまうので、どうもこれを直す必要があるみたいです・・・
(Pythonでは特殊な意味を持たない、文字として単体の「¥」は認識できないようです。)
試しに「¥」でre.search()してみると見事にエラーですもん(笑)
上:SyntaxErrorはおそらくre.search(r’¥’,t)の構文エラーが原因で、
下:AttributeErrorはt=‘a¥01’に問題があるからだと考えられます。
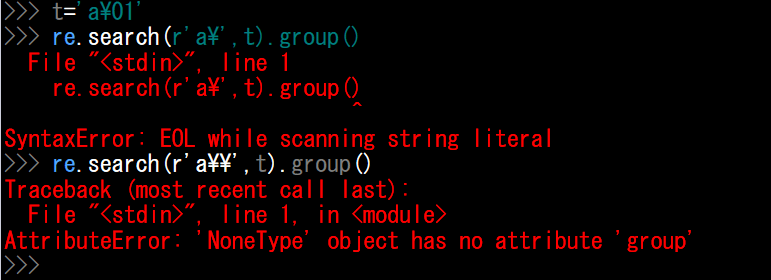
ちなみに「¥¥」だとちゃんと出力されます
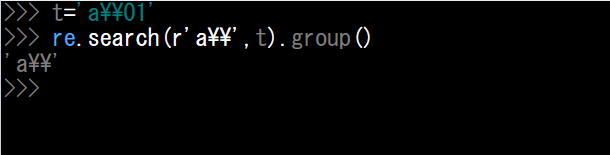
Pythonに限らずコンピュータープログラムに共通する一般的な事かもしれませんが
(ちょっとそのへんは無知ですごめんなさい)、
エスケープ文字「¥」は特殊な意味として
⦁特殊な意味を付与する働き-(ⅰ)
⦁(ⅰ)とは逆に特殊な意味を打ち消す働き-(ⅱ)
を持ちます。
「\\」で/(バックスラッシュ)」の他には、\nで改行、 \tでタブの意味をもつように、
特定の文字の前に¥を付けると特殊な意味を与えることができます。
ここでは文字通り逃げてしまう文字で、例えば\\「xこの部分を探索したいとき、\\「xを正規表現パターンとしてそのまま書いても、文字として探索することは不可能です。
例のように、正規表現パターンの直前にrを追加することで特殊な意味を打ち消し、ただの文字として探索可能となります。-(ⅰ)
一方で、一番最後のre.findall部分について、小数点を含む数値を探すには'([0-9]+[.][0-9]+)'のように[ ]で括って指定すれば可能な他、'([0-9]+\.[0-9]+)'と表記しても可能です。この場合の¥は特殊な意味を打ち消す為に使用しています。
ややこしいですね…(*_*;
「.」は正規表現での意味は “改行以外の文字パターン“となっているためそのまま'([0-9]+.[0-9]+)'と記載すると意図しない結果['0.12', '0.22', '0.25', '2020', '10-01', '000']が返されます。これを防ぐために「¥」を付けます。-(ⅱ)
まとめると、
◆ 正規表現パターン先頭に「r」を付ける意味
r '\\‘ r’\n’ r’\t’
“\n“のような特殊な意味を打ち消して文字として認識させる効果
123¥456のように、特殊な意味を持たない文字列の場合は例外。認識できない。
◆ 正規表現パターン直前に「¥」を付ける意味
'\*’ ‘\.’ ‘\?’
“\+正規表現パターン記号”で正規表現の特殊な意味を打ち消し、¥以降をただの文字列として認識させる効果
最後に、見つけたパターンを別の文字列に置き換える方法を参考までにメモしておきます。
◆ [reを使った文字列の置き換え]
特定のパターンに対して、別の文字列に置き換えを行いたいときはre.sub(正規表現パターン,置き換える値,対象文字列)を使います。
例えば
re.sub('\\\[^0-9]+', '', pattern3)
これを実行すると
'0.12 0.22 0.25 202010-01 000.csv'
が結果として返ってきます。
このように、細かい設定とパターン記号にさえ慣れれば、決まった形式のデータに対して正規表現を使うことによって柔軟に処理してくれそうですよね(^u^)
サブ知識として覚えておけば、複雑になりがちなプログラムも案外スッキリ分かりやすい表現ができるのかもしれません♪
では長くなりましたが今日はここまでです。
