 06-6657-5130
06-6657-5130 sales@hydrolab.co.jp
sales@hydrolab.co.jp蛇使いな彼女BLOG
【第40回】 htmlファイルからのデータ抽出②―htmlファイルからスクレイピング
2021.08.06

こんにちは、前回はBeautifulSoupというライブラリを使ってhtmlファイルの読み込みを行いました。
↓
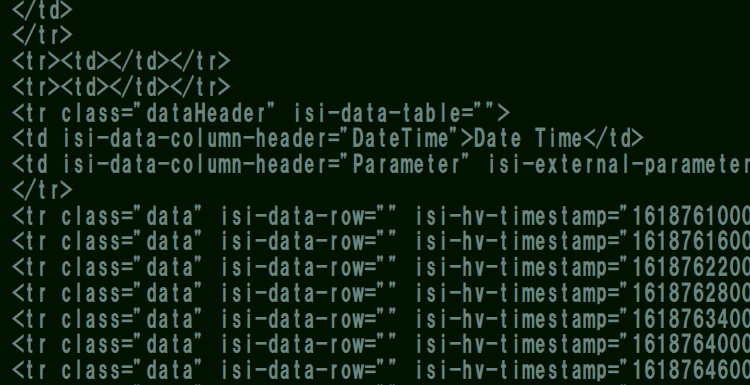
今日は読み込んだhtmlファイルから特定の要素を選択して抽出する方法を紹介します。
要素の取得が可能なメソッドにはfindタイプかselectタイプの2種類ありますが、今回はfindタイプのfind_all() を使います。
find_all(要素名、属性名) の引数で指定可能です。(※findAll()でも同様)
試しにBeautifulSoupで取得したソース内で<tr class=”data” isi-data-row”” …>の計測データに当たる部分をタグ要素と属性名を使って抽出しますね。
★タグと属性での抽出
■要素名で指定した場合:soup.find_all('tr') ↓
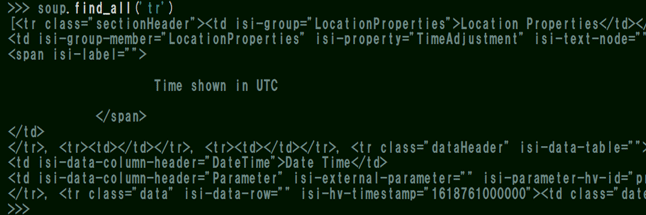
「tr」タグで始まる要素を全て抽出します。計測データや見出し部分も一緒に抽出されました。
■属性名で指定した場合:soup.find_all(class_='data')
↓

class属性が「data」の要素を全て抽出します。これは計測データのみ抽出されました。
(1行だけ?と思うけど、リスト形式で右端までぎっしりデータが詰まってます↑)
ここまで出来たら、次は横長のデータから縦×横の表形式に整えます。
↓
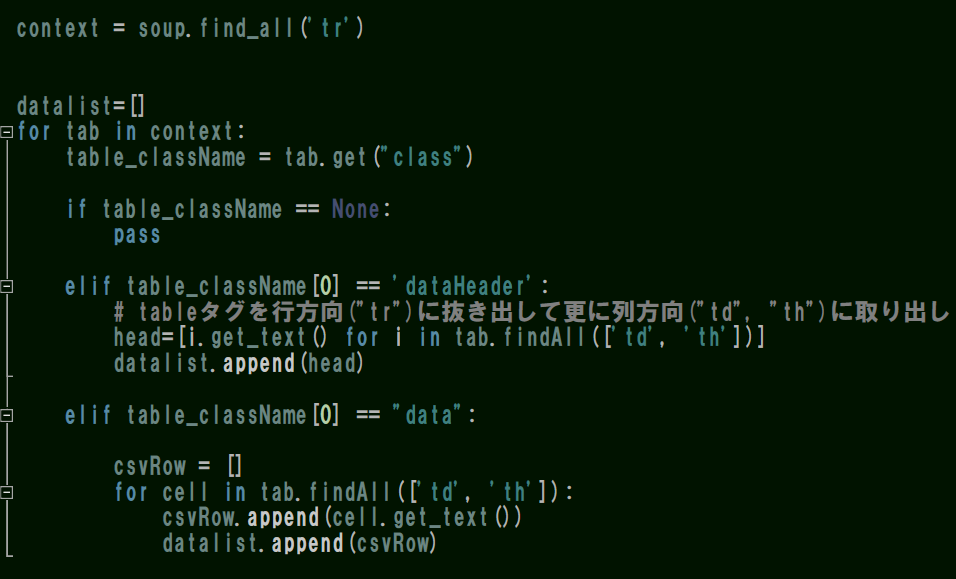
これを実行すると、
↓
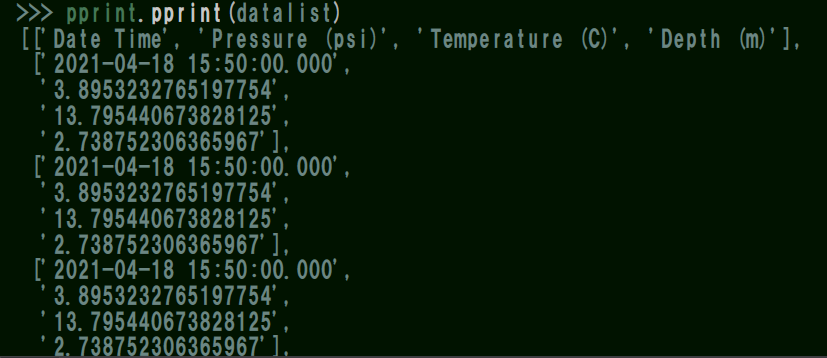
1行ごとに計測データが抽出出来ています✨
後はpadasのDataFrameで表形式にしてもいいですが、以下のように繰り返し処理の中でcsvファイルへの書き込みをしてもOKです。
★書き込み参考例

最後から2行目
d.loc[:,'Depth (m)']=d['Depth (m)']+loatf(lv)
このlv部分に箇所に適当な数値を入れてd=Convert_csv()実行すると、実行中のフォルダ(ここではVuSituHTML.pyが存在するフォルダ)にcsv形式のデータが保存されます。
↓
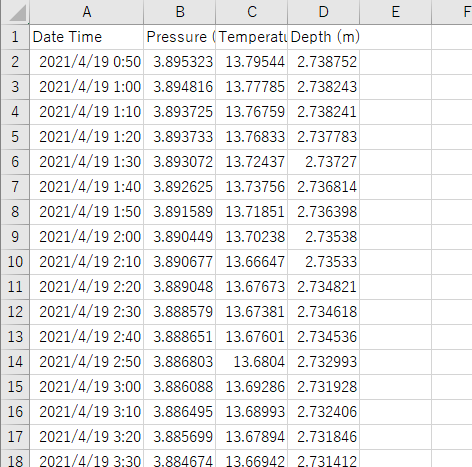
また関数の返り値dには、lv部分で指定した数値を基準に、Depth(m)部分を書き換えた新しいデータが返されます。
↓
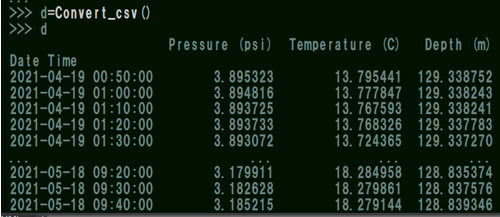
なぜ書き換えの必要があるのかという点について、プログラミング的には正直あまり重要ではないのですが、水位計の測定原理としては知っておいて損は無いと思うので次回紹介したいと思います。
では今回はこれにて終了!
