 06-6657-5130
06-6657-5130 sales@hydrolab.co.jp
sales@hydrolab.co.jp蛇使いな彼女BLOG
【第58回】 ライブラリ編2ー#2.機械学習ライブラリscikit-learnのスケーリングについて
2022.05.06

皆さんごきげんよう(^_^)v
今日はscikit-learnに挑戦する第一歩として、sklearn.preprocessingというパッケージを使ってデータのスケーリングにチャレンジしてみたいと思います。
機械学習・深層学習の前提として、多くは何らかの数値で表した特徴量から、対象データの特徴を学習し、予測や分類を行います。その為、
①用意したデータの特徴にテキストが含まれている場合、これを仮の数値に置き換えたり、
②また特徴量によって単位が異なるデータを扱う場合、値が極端なデータが含まれている場合にスケール調整をするなど、
これら前処理をしっかり行う事で予測・分類精度が向上する事があります。
sklearn.preprocessingについて簡単に説明すると、これは上記の②にあたる処理で、単純に内部計算にかかる負担を軽減する効果もありますが、特に使用する学習アルゴリズムがデータの分散を元に評価する場合に有効です。
一般的によく利用されるスケーリング手法は、正規化や標準化です。
今日は外れ値を含んだデータを用意し、
sklearn.preprocessing.StandardScaler:標準化
sklearn.preprocessing.RobustScaler:外れ値に強い標準化
これらを使ってスケーリングした結果データがどのように変化するか確認したいと思います💡
RobustScaler
RobustScalerとは四分位範囲を使ったスケーリングで、外れ値に影響されにくいという特徴があります。このスケーラーを使う事でデータクリーニングを含む前処理が楽になると良いんですが…。
ではコードをみていきましょう。
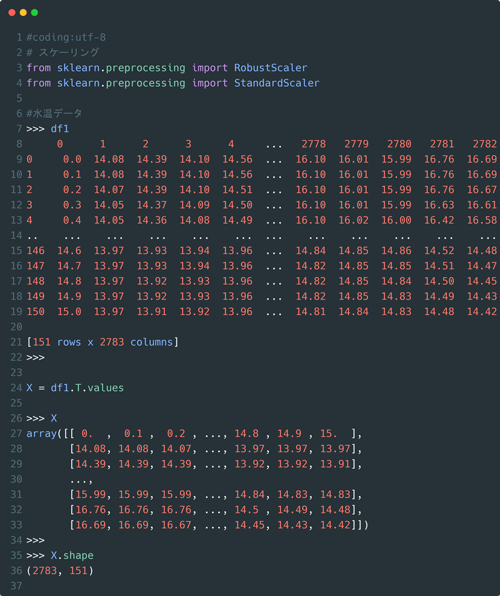
df1は某ダムの水温データで、行方向に水深、列方向に時系列という並びになっています。
各列単位は統一されていますが、外れ値で値の変動が大きい箇所があります。
今回使うスケーラー(StandardScaler/ RobustScaler)はいずれも列方向に処理を行う仕組みなので、まずはX=df1.T.valuesで行列の入れ替えを行います。↓

行列の入れ替えが出来たら、各スケーラーを対象データに適応させます。
今回は表層0.5m地点の時系列データを参考に結果を見てみましょう。
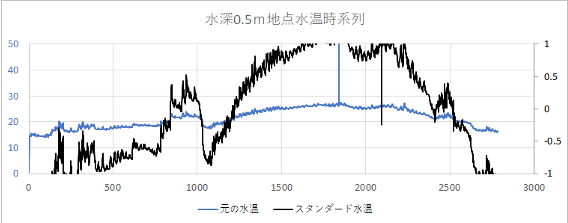

スタンダード・ロバストどちらも元の値と比べてスケールが小さくなっています。
ほとんどの値は1から-1の範囲に収まっていますね。
サンプルデータの数が多い場合はこのようにスケールを小さくすることで計算にかかる負担を軽減できます。
外れ値
次に外れ値についてです。
X軸の1800付近にある外れ値は「元の水温データでは169℃となっています。
「スタンダード水温」では31.90、「ロバスト水温」では20.97。
スタンダードは外れ値に引っ張られたマッピングとなり、ロバストの方が外れ値の影響を受けにくいマッピングとなっています。
スタンダード・ロバストともに外れ値自体はスケーリングされた後もデータに残ったままとなってるので、<169℃のようなあり得ない数値の箇所はいずれにせよ除去が必要となります。
標準化を使う場合は最初に外れ値を全て取り除いてからスケーリングするのが適しており、ロバストの場合はスケーリング後に外れ値を取り除いたとしても、他の値への影響が少ないという事ですね💡
実世界の体重と身長の関係や所得データなどと違い、水質データ時系列に関しては、例えばグラフ上の「元の水温データのX軸2000付近の水温20℃のという箇所も(計測値自体は外れ値ではないですが、前後の値から不自然と判断できる為)なるべく外れ値として扱わないといけない分、前処理は大変です💧
モトハシがサイキット・ラーンのスケーリングを試して思ったことは、
結局外れ値や欠測値を都合良くはじく機能は存在せず、地道に手作業で修正していくしかないのだ…と痛感(゚´Д`゚)
“機械学習ライブラリのスケーリング機能なら外れ値除去機能くらい付いていそう“という思惑は見事に裏切られましたという話でした(笑)
